



Introducing AttuneBench
Kate Lubrano
,
May 27, 2026

Why measuring EI Matters
Roughly 13% of US young adults use LLMs for mental health support (McBain et al., 2025), with therapy and companionship now among the most common LLM use cases. In these personal contexts, getting it wrong has real costs: hallucinated advice in vulnerable moments, missed signals of escalating distress, validation of harmful behavior, or inconsistent responses when users need reliable support. Recent work has begun documenting these failure modes in mental health uses (Moore et al., 2026). Measuring emotional intelligence (EI) in LLMs is hard because EI is private knowledge. Only the participant in a conversation knows what they felt and what kind of response they actually wanted.
That's exactly where existing EI benchmarks fall short. They score against proxies (third-party annotators, LLM judges, scenario templates with pre-written answers), which fail to capture the complexity of genuine human interaction. Issues like drift across turns, miscalibrated tone, and recovery from misreads, can only be identified in multi-turn conversation with real humans on the other end. AttuneBench aims to address these gaps, allowing for more accurate identification of model strengths and weaknesses across different facets of EI.
How AttuneBench works
As can be observed in humans, EI is not a single skill. Someone might be excellent at perceiving how others feel but struggle to manage their own reactions, while another might reason emotionally well but miss social cues. This concept is captured by the Mayer-Salovey-Caruso Four Branch Model, treating EI as a set of distinct, measurable abilities rather than a single trait. AttuneBench scores LLMs on each of those abilities (perceiving emotion, understanding it, using it to guide thought, and managing it in interaction). Grounding the benchmark in the same dimensions psychologists use for human EI allows us to turn such a complex concept into specific, measurable behaviors. We also score response generation, plus conversation-wide measures like mood trajectories and the participant's self-identified conversation goals.
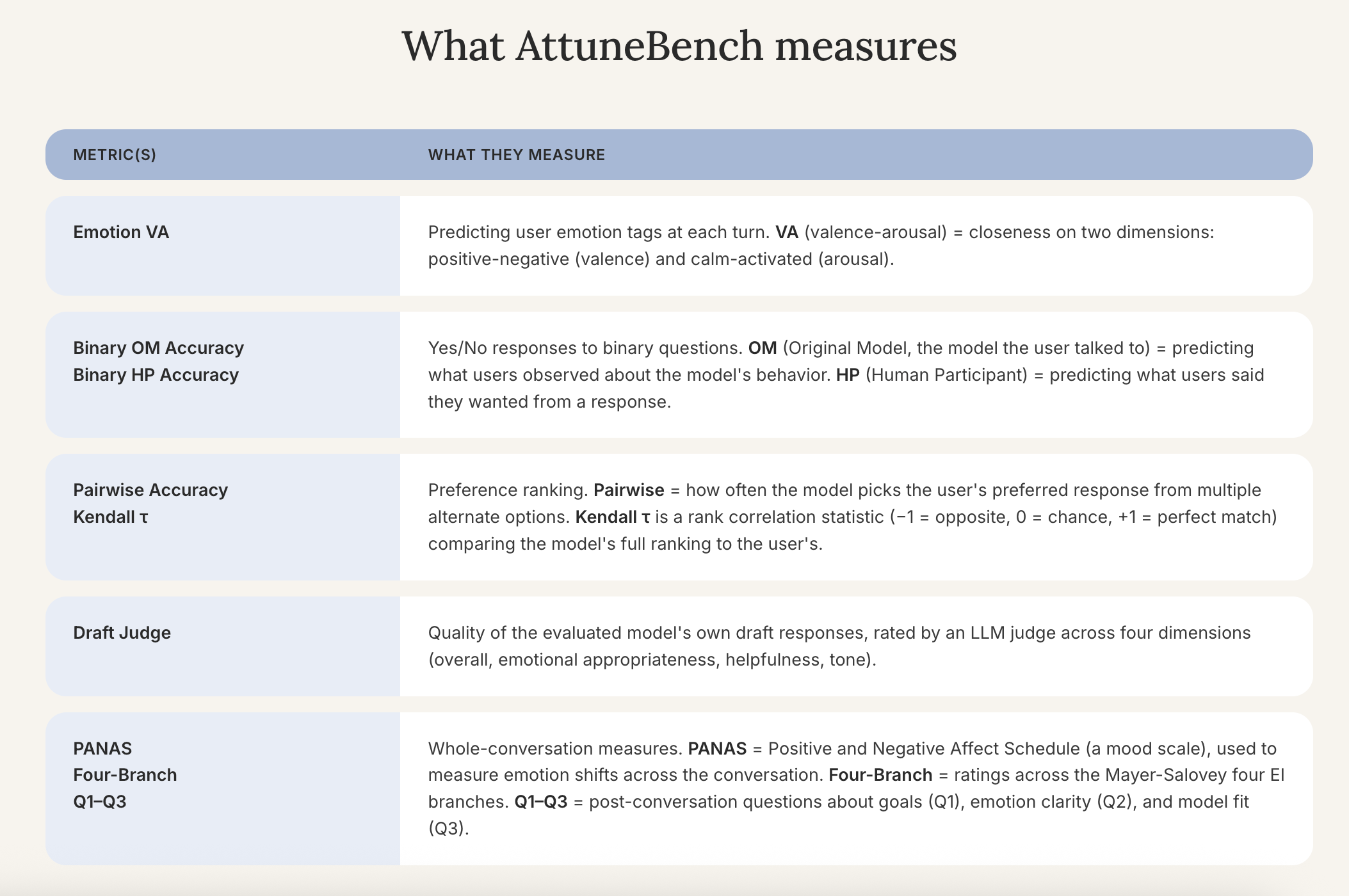
AttuneBench is grounded in 200 real multi-turn conversations between humans and LLMs. Participants labeled their own emotional state, observed behavior of the original model, and which alternate responses they would have preferred at each turn, contributing over 50,000 annotations across the dataset. Participants also completed screening and demographic questionnaires before the study, enabling subgroup analyses.
When the benchmark is run, the evaluated model reads each conversation turn-by-turn and predicts what the participant labeled: what they felt, which behaviors they noticed, which responses they would have preferred. We grade each prediction against the participant's actual label, producing per-metric scores that show where models match human experience and where they diverge, the core of what EI in conversation requires.

Evaluation (right) scores any new model against those annotations.
What we found
In our initial experimental run, we evaluated 11 frontier models from Anthropic, OpenAI, Google, Mistral, xAI, Alibaba, and Xiaomi. A few patterns from this run are worth highlighting.

Perspective gap.
All 11 models scored higher when predicting what the model did rather than what the participant wanted (p < 0.001 each, gaps of 3.0–7.6 pp). A model can read what happened in a conversation accurately and still miss what the user wanted from it. In an emotional conversation, what the user wanted is the whole point. Missing it means a model can produce confident-sounding responses that fail the people they were meant to help.
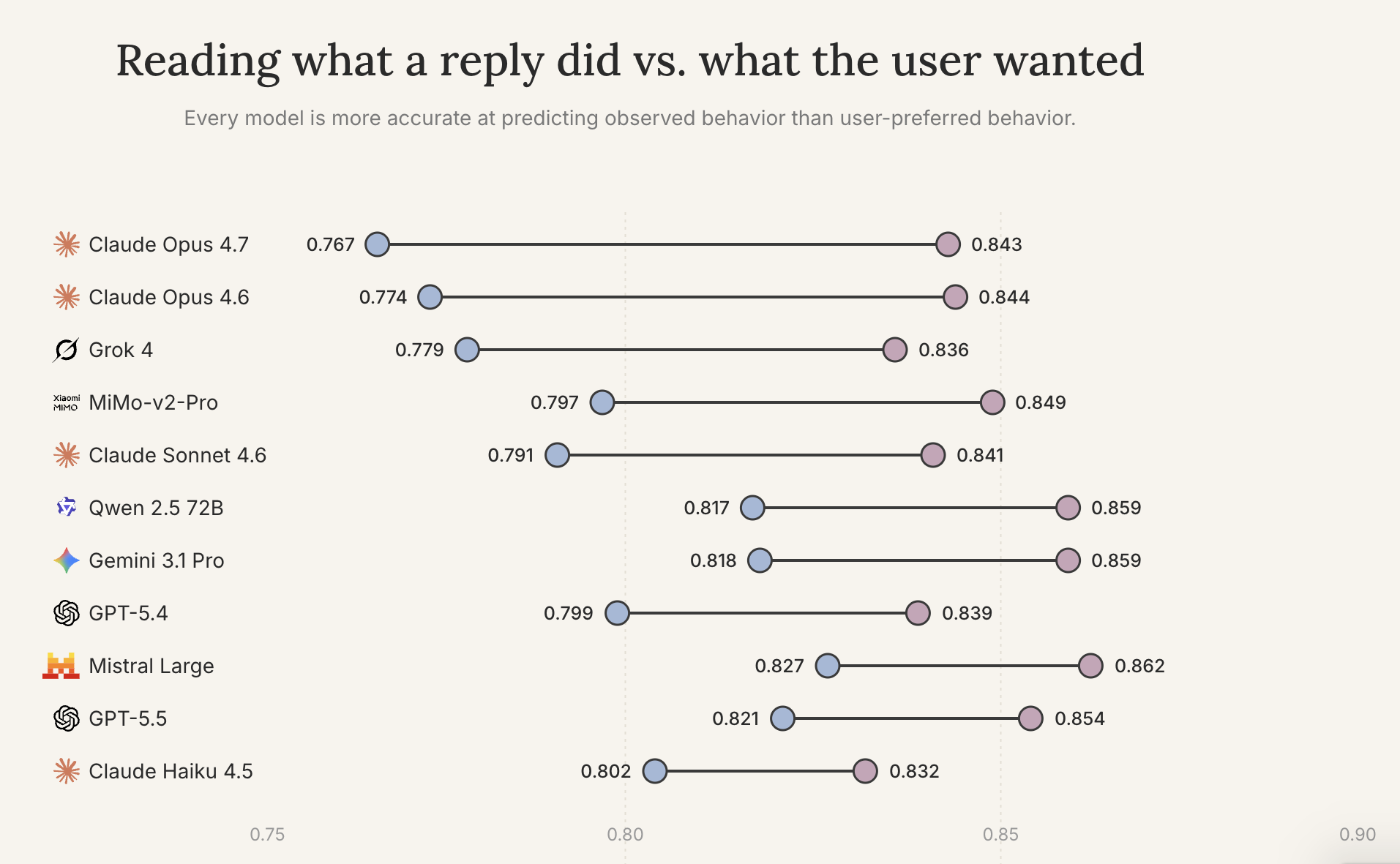
Longer lines mean wider gaps.
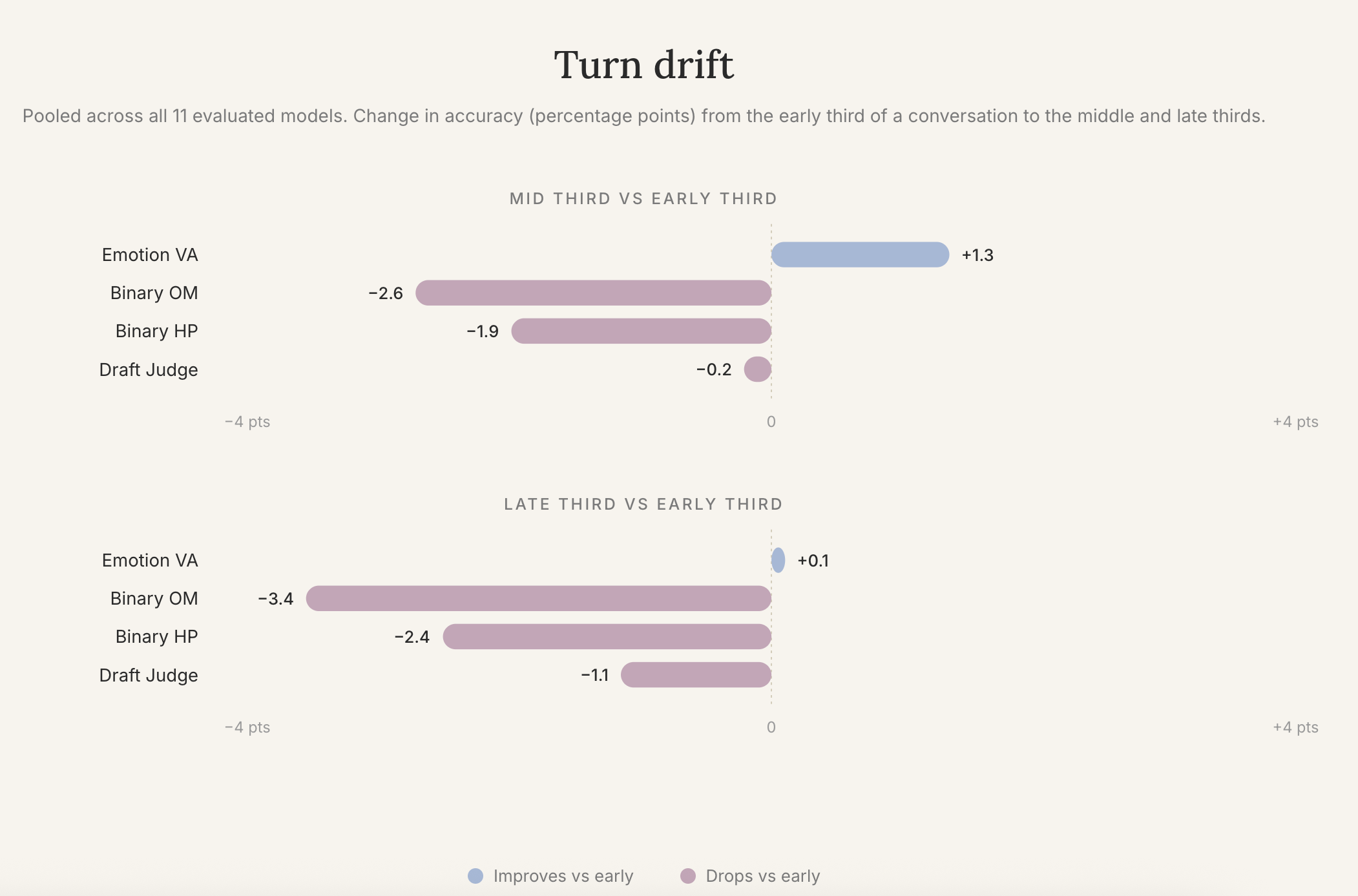
Turn drift.
9 of 11 models read behavior less accurately in the last third of a conversation than in the first: pooled Binary OM Accuracy drops from 86.6% to 83.2%. Emotion-tracking accuracy doesn't follow the same shape, it actually peaks in the middle third before returning to near where it started. More context isn't always more understanding, and the kind of context that helps depends on what's being measured.
Clinical affect gap.
Emotion-tracking accuracy drops 35% for participants reporting any mental health diagnosis (0.310 → 0.202, 11/11 models). Observable behavior is actually slightly easier to read for anxiety/depression participants (Binary OM Accuracy 0.878 vs 0.837), likely because these conditions surface in more legible behavioral patterns, but what's harder to read is the affective state underneath. Models can see what these users are doing more accurately than they can read what they're feeling. It's a worrying finding: models misread emotions most for users navigating mental health conditions, exactly the group where those misreads could carry the most risk.

Capability split.
- Anthropic's Opus 4.7 is best at picking which response users prefer from provided alternatives (Pairwise Accuracy 0.646), but worst at predicting what specific features users said they wanted in a response (Binary HP 0.767)
- OpenAI's GPT-5.5 is the only model in the top tier on both turn-by-turn user prediction and conversation-wide ratings.
- Google's Gemini 3.1 Pro leads at tracking what users felt at each turn (Emotion VA 0.278)
- Mistral Large shows the inverse profile of Opus: leading at predicting what behaviors users wanted (Binary HP 0.827), but lower at picking the user's preferred response (Pairwise Accuracy 0.517)
No single model leads on every measurement. 5 of 11 models rank responses in the opposite direction from what humans actually preferred on average (negative mean Kendall τ).

A different model leads each, with per-panel ranges zoomed to make the gaps visible.
The paper covers full methodology, metric definitions, and additional findings, including mode comparisons, topic effects, and more.
Closing the Gap
LLMs are already being used for emotional support, but their EI as a capability remains under-measured when compared to skills like coding, reasoning, or math. A coding error can produce a bug, but an emotional misstep can hurt the person on the other end. Real emotional conversations are complex. EI isn't a single capability, and models that excel on one dimension often fall short on another. AttuneBench enables granular measurement, giving labs the specifics to identify gaps in their models and work towards closing them.
How attuned is your model?
AttuneBench v1.0 is open, run it and find out.
This work was a collaboration between Pareto AI’s Research team, led by Mark Whiting, and Thoughtful Lab, led by Karina Nguyen. Special thanks to the participants who made this dataset possible.