



The bar exam was not designed for this
Phoebe Yao
,
Mar 13, 2026

Professional credentialing is approaching a crisis. A better methodology for measuring expertise already exists. It comes from model post-training, and neither the people building it nor the licensing bodies they could help have connected the dots.
This piece tries to close that gap for those whose credentials are at stake.
What expertise is becoming
The human data industry is an early indicator of where professional expertise is going. The stages we've moved through to train models are the same stages professional work is moving through now.
Stage one: human-in-the-loop. In early human data, we showed models examples of good human work and gave them feedback on our preferences. That loop is now arriving as the day-to-day reality of professional work. Current credentialing was barely able to proxy human capability alone. It was never built for anything beyond it.
Stage two: humans-on-the-loop. Professionals overseeing AI agents that work independently, rather than collaborating on each step. In human data, experts are already here: contributing task specifications and verification insights, defining what good looks like rather than just showing it. The expertise this requires isn't subject knowledge alone. It's understanding where agents fail and designing the rubrics to catch it.
Stage three and beyond. Experts working at the level of task types and verification taste: which categories of problems are worth making trainable, and what a good verifier needs to capture. Each step up makes the previous measurement less relevant.
Why current measurement fails
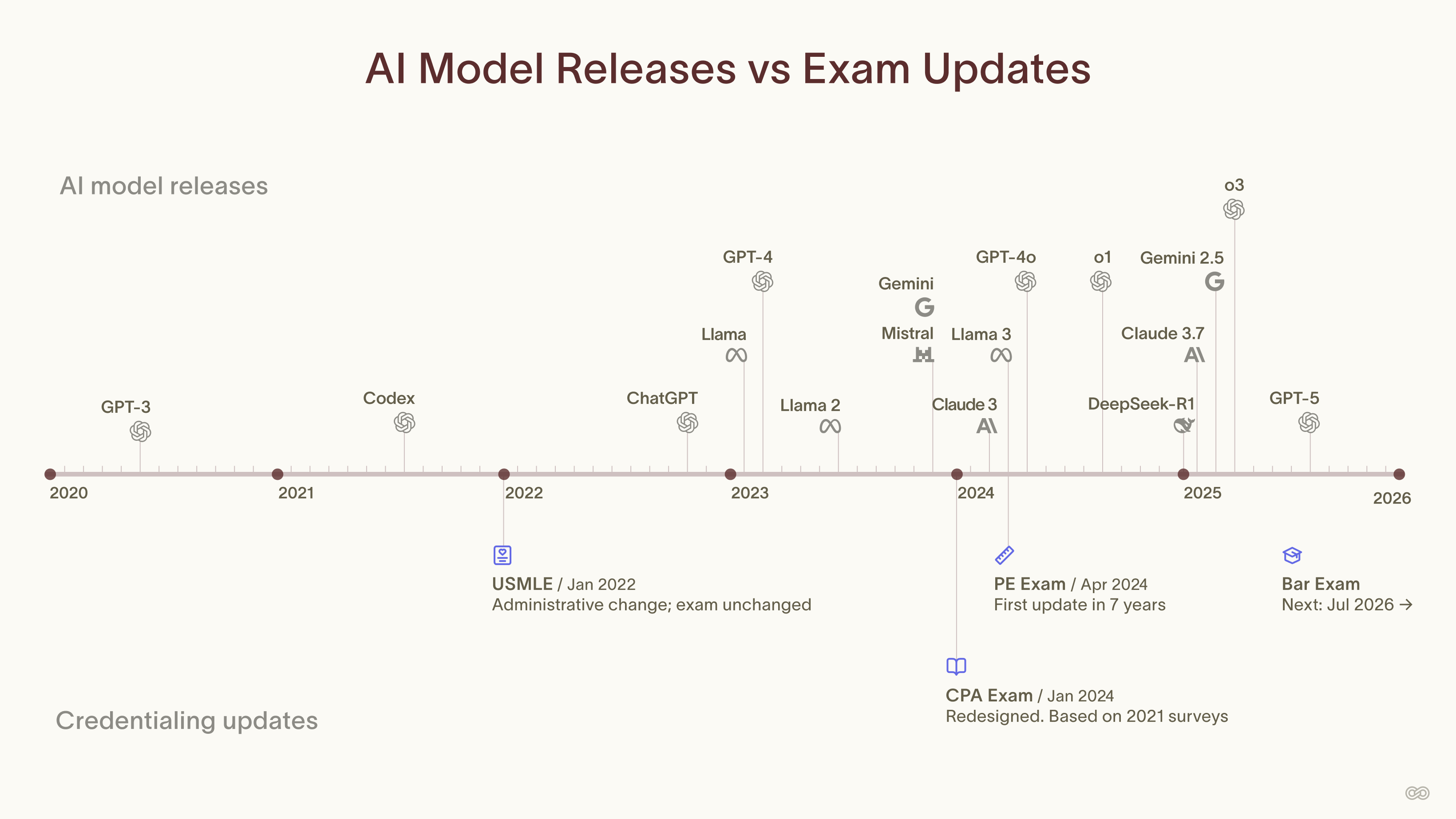
The job changed. The test didn't.
The job of a professional today is to work alongside a model and produce better outcomes than either could alone. Measuring that uplift requires assessments calibrated at the edge of current model capability in the specific domain being credentialed: tests hard enough that the model alone fails, so the human contribution becomes visible. No current licensing exam is designed that way.
Surface features of competence are now separable from competence itself.
Professional assessments are functioning as shallow verifiers: they were designed to reward demonstrated competence, but models have learned to satisfy them without it. GPT-4 scores near the 90th percentile on the bar exam. GPT-4o tops 94% accuracy on USMLE Step 2CK. Both benchmarks test recall and pattern-matching under exam conditions, the same thing standardized tests have always tested. Neither was designed to distinguish genuine reasoning from pattern retrieval.
This was always a latent vulnerability, and we call it reward hacking: the policy maximizes the reward signal through unintended shortcuts, satisfying the metric while missing the objective. Models are great at finding shortcuts, and now humans are too. A meaningful number of applicants to our medical expert programs are doing exactly that: presenting credentials while copy-pasting model responses. The fraud made it past the credential check, past the written screening, and only got caught when we got them on a call with a real clinician.
A test that doesn't move is measuring less every year.
New models come out every quarter. Each release shifts what models can do without any professional judgment at all. A credentialing exam updated every few years is measuring a different profession than the one it was designed for. Assessment cadence needs to match model cadence.
What measurement should look like
Current exams don't account for what models can already do. A well-calibrated assessment sits at the edge of model capability. Roughly 70% of the model training tasks we build need adjustment before they're useful: a task that's too easy, too hard, or poorly designed produces no signal.
Current exams check outputs. A robust verifier checks the reasoning behind them. A professional who arrives at the right answer through pattern retrieval looks identical to one who reasoned their way there, unless the assessment is built to close off reward hacking.
Current exams are static. Model capability isn't. A credentialing body that updates its exam every few years isn't measuring a professional's value over current models. It's measuring their value over whatever models existed when the committee last met.
What comes next
Professional expertise is shifting faster than the systems built to measure it. The fraud, the shallow verifiers, the static exams are symptoms of a measurement infrastructure designed for a static definition of expertise. We need a way to continuously update our understanding of what expertise actually requires.
A new methodology is already being built, across thousands of model training runs. The human data industry and post-training researchers are developing robust verifiers, calibrated difficulty, and shifting assessments: the same infrastructure that credentialing bodies need. Unlocking it for credentialing is the next step.
That infrastructure, applied to credentialing, isn't a better version of what exists. It's a different thing entirely: a live, dynamic read on human expertise that recalibrates against the frontier in real time. A credential is a snapshot. This is a signal.