



Verifier engineering is the moat
Phoebe Yao
,
May 21, 2026
.png)
All good verifiers are alike. Each bad verifier is bad in its own way.
In RL post-training, the frontier of verifiability is the frontier of learnability. Crafting new verification methodologies is the binding constraint on translating expert judgment into trainable RL signal. Building that verification signal for frontier labs is a fascinating part of what we do as a data provider. This is how we think about the work.
What is a Verifier?
A verifier is a mechanism that evaluates rollouts against a standard and produces verdicts suitable for optimization.
In reward-based training, the verdict serves as, or feeds into, the reward function. Verdicts are also used to drive quality control and failure-mode analysis.
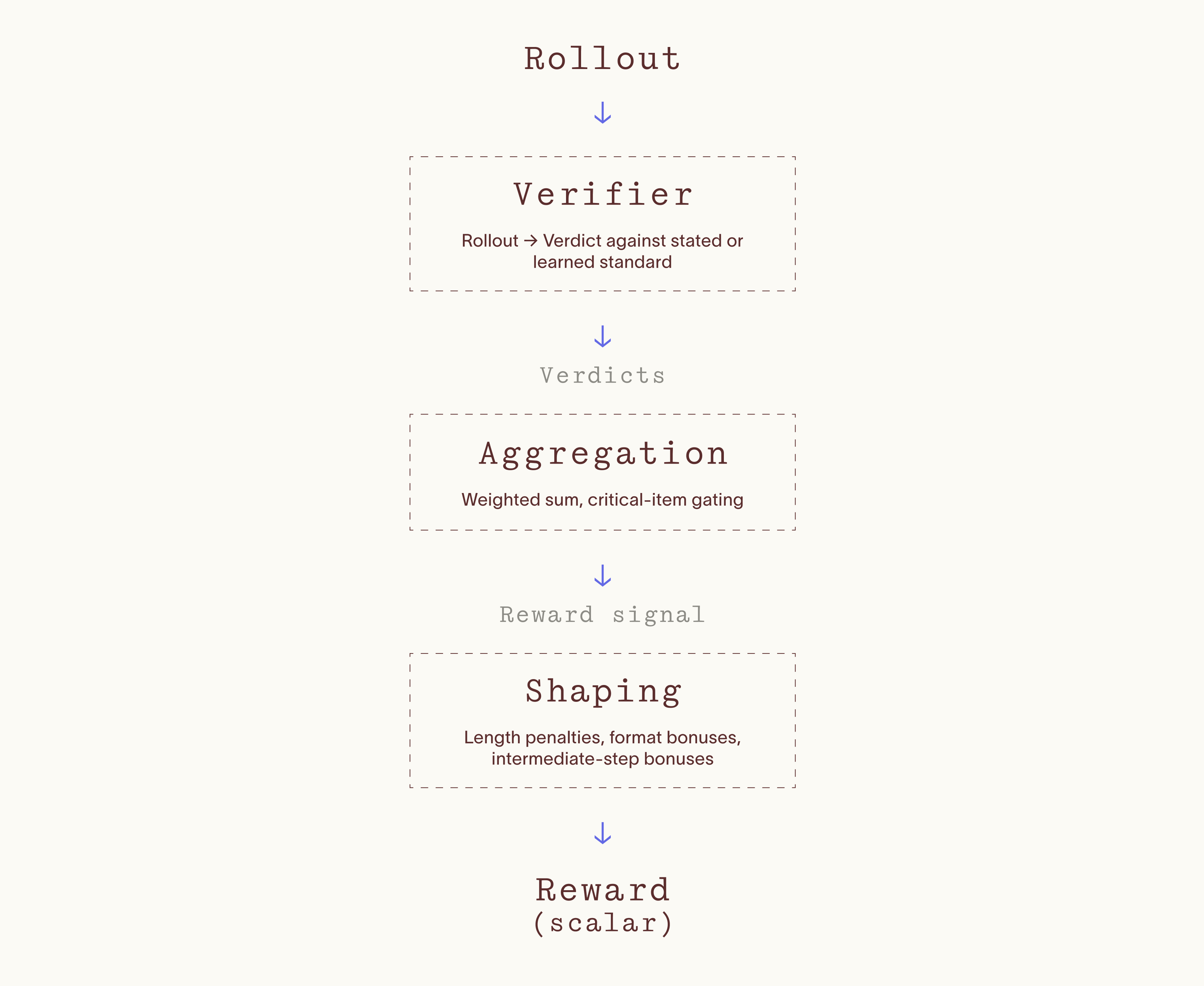
In production, verifiers are usually a hybrid of modalities:
- A programmatic check verifies exact outputs where it can, and falls back to an LLM judge with a rubric for the subjective parts.
- Programmatic scoring handles the outcome while a judge grades the process.
- An agent runs programmatic checks from its own toolset to verify parts of a task.
The most common building blocks:
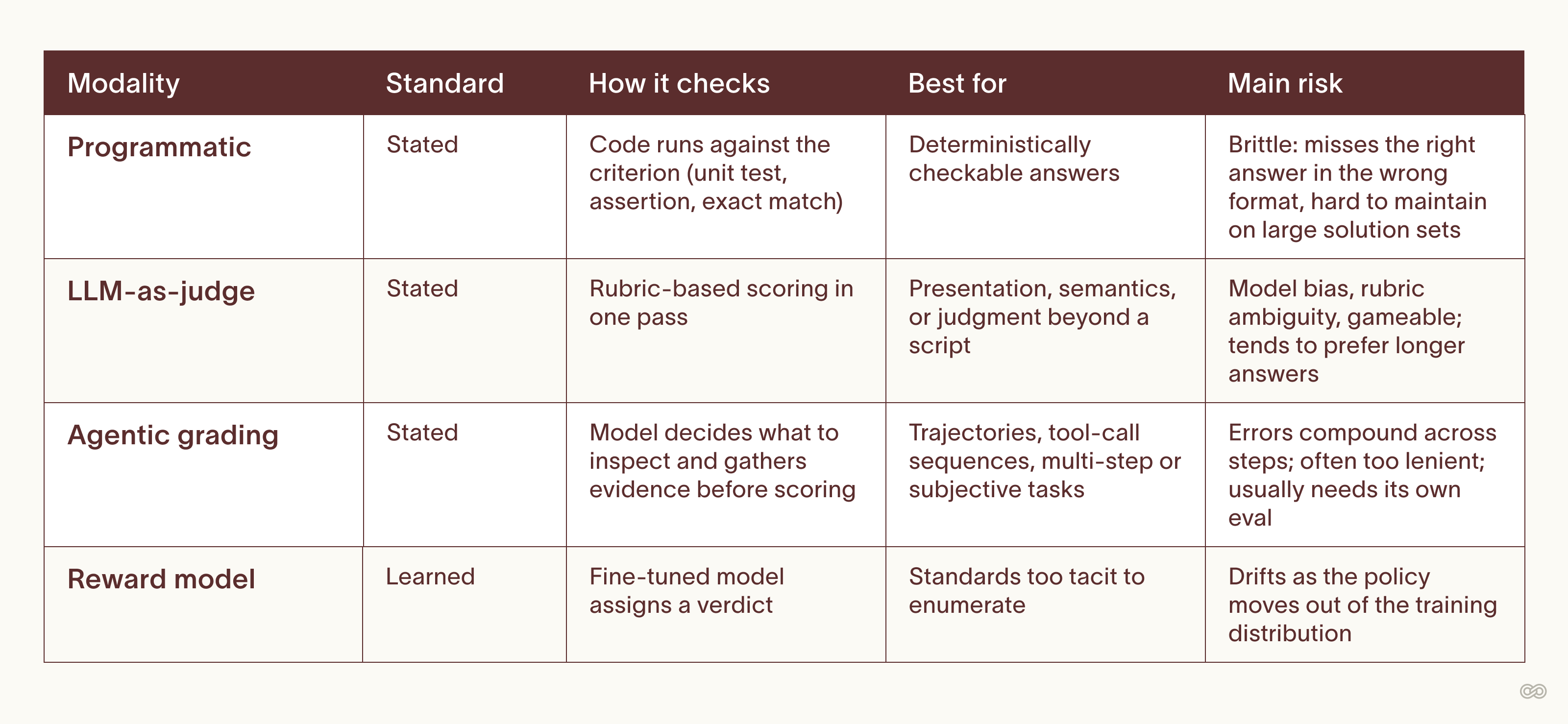
The more sophisticated the capability, the more sophisticated the verification method needed to deliver the highest-fidelity verdict. Programmatic checks for code are straightforward, but mechanisms that define successful legal reasoning or emotional intelligence need careful, focused R&D.
Designing a High-Quality Verifier
What does it take to build verifiers with low false-positive and false-negative rates? We break quality down into five properties:
- Consistency. Does the verifier produce stable verdicts across repeated rollouts?
- Calibration. Do verdicts track actual task success as a domain expert would judge it? This is the verifier's construct validity.
- Coverage. Does the rubric check the material requirements of the task, without omitting necessary criteria or adding unsupported ones?
- Robustness. Does the verifier stay reliable under optimization pressure, or can it be reward-hacked?
- Auditability. Can the verifier's behavior be inspected, reproduced, and calibrated?
No single verifier maximizes all quality dimensions, so it comes down to choosing the methodology and mix of modalities that best fit the pipeline, which depends on the attributes of the capability being verified:
- Ground-truth structure. What makes the output correct, a binary decision or a judgment call? This decides whether a programmatic check is even possible.
- Output shape. A single number or structured JSON has different verification properties than a tool-call sequence, a mutated environment state, or a free-text summary.
- Stakes. For safety-critical evals, false negatives cause real harm and must be avoided, which changes how the rubric is weighted.
10 Common Failure Modes
Nearly every verifier is imperfect, and the difference between good and bad is subtle enough that catching it takes careful review even for experienced teams. After a year building verifiers for frontier labs, here are the 10 failure modes we see most often.
1. Rubric weighting
In our experience, about 70% of experts get rubric weighting wrong on their first attempts. To illustrate, here's a real task we reviewed, with eight criteria summing to 10 points:
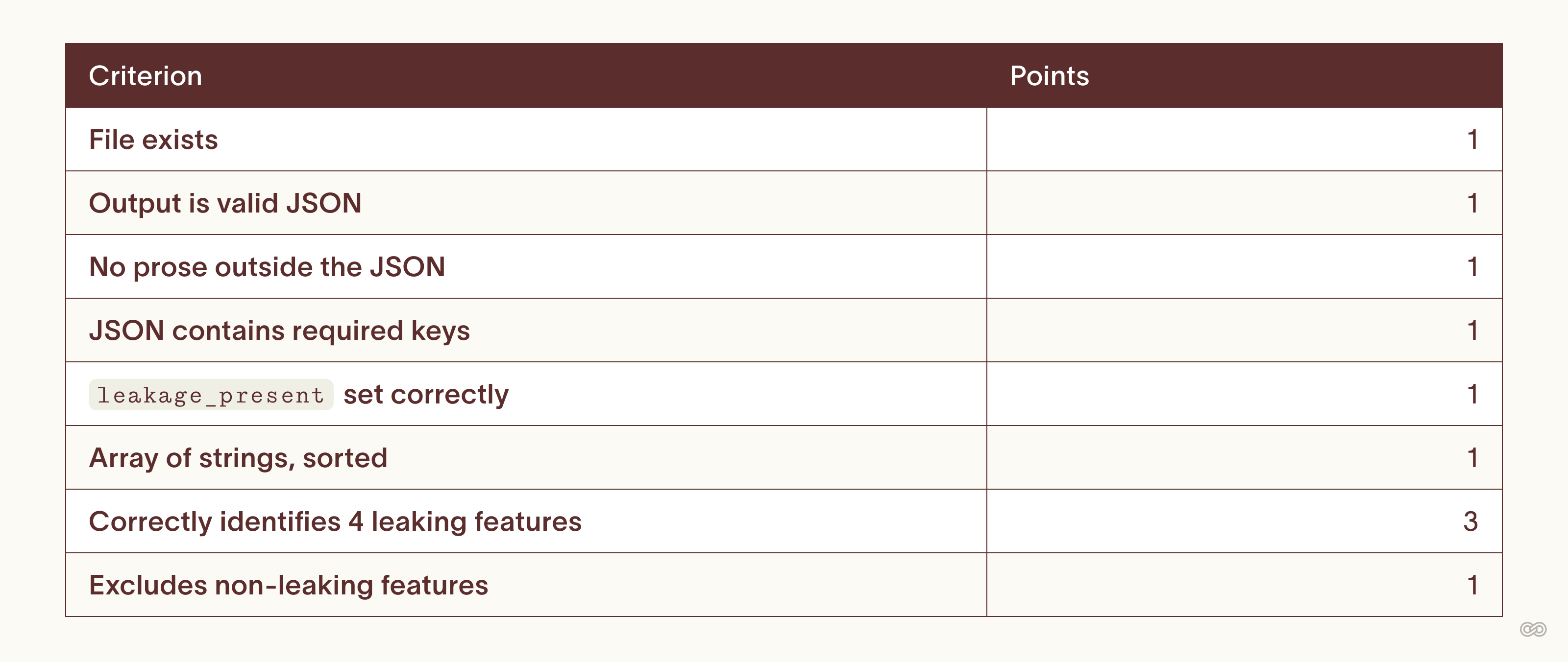
A model can score 9 out of 10 by writing valid JSON, listing every feature as leaking, and just dropping a single point for excluding non-leaks, which happens to be the only reasoning criterion that checks discrimination.
Fix: make the reasoning criteria gating, or rebalance so a rollout can't pass on formatting alone.
2. Gameable problems
Gameable problems have a default answer the model can guess without reasoning, or a rubric that doesn't penalize lazy strategies.
Example: the leakage example above rewards the model for flagging features as leaky but doesn't penalize wrongly including non-leaky ones, so naming every feature scores highly. Outlier-detection tasks have the same shape: if the answer is most often "none," guessing it becomes a cheap default way to score without completing the actual task.
Fix: score both directions, so over-flagging is penalized as much as missing, and defaults aren't rewarded.
3. Tolerance
Tolerance is about what counts as equivalent. A verifier that doesn't allow for natural variation in correct answers will reject good trajectories.
Example: a type mismatch, where a string, an int, and a double for the same value aren't equal under a naive programmatic check.

Decimal precision is another: whether 1.0 equals 1.001 depends on the task. When tolerance is too tight, false negatives pile up and good trajectories go unrewarded. Programmatic checks fail here more than judges, since a script compares literally where a grader can rule on equivalence.
Fix: define equivalence explicitly for the task, or use a grader for criteria where valid answers vary.
4. Binary vs partial credit
Binary scoring throws away signal on near-misses:

This collapses the gradient with a brittle verifier that can't distinguish a near-solution from a non-starter, or a shortcut from a genuine solution. The weakness in calibration and robustness compounds in long-horizon agent tasks.
Final outcomes can also benefit from partial credit. For instance, the task "train a classifier and report accuracy" has no single right number, so a verifier could grade the approach (the EDA, the model choice) alongside a banded score on the result (1.0 if R² > 0.9, 0.7 if R² > 0.6, and so on).
Fix: award partial credit for intermediate steps, and for final outcomes where correctness is tolerance-based.
5. Redundant checks
Redundant checks happen when two criteria pass or fail together because one condition drives both, so the verifier double-counts a single capability.
Example: a rubric that scores "query parses" and "query references valid tables" as separate criteria is scoring well-formed SQL twice.
Fix: check which criteria are statistically correlated across production rollouts, and collapse the ones that always move together.
6. Grading non-determinism
Real tasks have real ambiguity. Professionals reason from incomplete information using expert judgment, and verifying that reasoning is the hardest problem we face. Rigid rubrics that expect one solution penalize valid alternatives; lenient rubrics fail to check whether the reasoning was sound at all.
Approach: agentic grading against a rubric that specifies what counts as valid reasoning across multiple correct paths. The burden shifts to rubric design.
7. Over-instrumented rubrics
The opposite of missing coverage: too many intermediate or method-specific checks bias the score toward one expected solution path, even when other valid approaches solve the task.
Example: a rubric for a data-summary task that scores specific column values, exact subtotals, metadata fields, source choices, and sort order, all on top of the final answer. It rewards the expected method instead of judging whether the result is correct.
Fix: check the final outcome and the genuinely load-bearing steps; drop checks that only encode one path.
8. Multi-output aggregation
When a task requires several final outputs, averaging rubric scores lets a wrong answer pass.
Example: a prompt asks for total, max_id, and count, equally weighted. The solver gets max_id wrong but still passes because the average clears the threshold.
Fix: gate pass/fail on all critical outputs, and use partial credit only for diagnosis.
9. Agentic grader reference discipline
An agentic grader should grade against the rubric and the provided ground truth, not substitute its own answer.
Example: the reference says 573, but the grader recomputes the answer under its own assumptions, lands on 640, and passes the run, overriding the ground truth it was supposed to enforce.
Fix: constrain the grader to the reference. Let it recompute only when explicitly told to verify the reference through a deterministic procedure.
10. Solution leakage
A verifier should detect and penalize answers that came from information the solver shouldn't have.
Example: a solver prints the expected answer after reading a hidden solution.md or expected_output.txt, instead of computing it. The output is correct, but it should fail.
Fix: inspect trajectory and file-access logs, and penalize any use of hidden answers, verifier logic, or expected outputs.
Why this is the moat
By now it should be obvious: verification is the encoding of taste. Anyone building verifiers is building hard-to-replicate, non-transferable alpha. For a lab, that alpha is faster capability gains. For a data provider, it's a durable offering.
Quality has no real ceiling, so cost is what gates verifier development. Agentic grading over 10,000 long-horizon tasks costs orders of magnitude more than near-free programmatic verification. The real art isn't "how do we verify this well" but "what is worth verifying well," a question that's as much about values as economics.
The capabilities that advance a field often aren't the easiest to verify. We think we can accelerate that work through a virtuous cycle, humans teaching models and models helping humans take on harder work, powered by novel verification methodologies that keep pushing the frontier of what's learnable.
Thanks to Cody Cooper, Vignesh Radhakrishnan, Dimitrios Chavouzis, Fahim Arefin for sharing the insights from their work that shaped this piece.