



Reinforcement learning from human feedback: everything you need to know
Ayush Parti
,
Nov 8, 2023

Ever wondered how ChatGPT is so good at producing such nuanced output, regardless of what you might throw at it? It somehow understands context, tone, style, length, and is even able to discern the intent behind a prompt with minimal guidance. The answer behind its accuracy lies in an LLM training technique known as RLHF.
In 2017, OpenAI unveiled the concept of integrating human feedback on a large scale to address deep reinforcement learning challenges, as presented in their paper titled "Deep Reinforcement Learning from Human Preferences."
This pioneering approach laid the foundation for involving human input in enhancing document summarization, creating InstructGPT, and ultimately, shaping ChatGPT.
As models become increasingly robust, the process of aligning them with our objectives will prove to be of utmost significance in guaranteeing their benefits to humanity.
But what exactly is RLHF? We've developed a comprehensive guide on how RLHF works, its significance, and benefits in the larger scope of AI and ML training.
What is RLHF?
Reinforcement Learning from Human Feedback, also known as RLHF is a machine-learning approach that uses human-provided feedback to train and improve reinforcement learning models. It leverages human guidance to accelerate and fine-tune the learning process, making it more effective.
Unlike traditional models, which rely heavily on predefined metrics and loss functions, RLHF harnesses the power of human feedback to fine-tune and align model performance with nuanced human values and preferences. It trains models to make decisions and receive feedback from human experts, including rewards, preferences, or demonstrations. This approach enables more efficient learning in complex and dynamic settings by capitalizing on human expertise.
What Are The Origins of RLHF?
RLHF has its origins in the broader field of reinforcement learning (RL) and machine learning. The fundamental idea behind RLHF is not entirely new but represents an innovative application in the context of training language models.
Reinforcement learning, which is a type of machine learning, has been around for several decades and is based on the idea of training agents to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. RL has been successfully applied in various domains, including robotics, gaming, and autonomous systems.
The specific application of RLHF in language models gained prominence with developments like Proximal Policy Optimization from OpenAI, which used human feedback as a reward signal to fine-tune the model's behavior. This approach started to gain attention around the mid-2010s as researchers sought more effective ways to train language models that could interact with users and respond to a wide range of inputs.
Traditional Learning Vs. RLHF
Within machine learning, two prominent strategies emerge: traditional learning and reinforcement learning from human feedback (RLHF). These strategies vary notably in their approach to managing the reward function and the extent of human involvement. In this section, we dive deeper into both.
Traditional Learning
In conventional machine learning, the reward function is typically predefined and static. The system is trained using a large dataset of labeled examples, and the "reward" comes from how accurately the model can predict or classify new data based on this training. Essentially, the model learns to make decisions by finding patterns in the historical data it's been fed. Human involvement in traditional learning is primarily front-loaded.
Experts prepare and label the dataset, then design and tune the algorithms. Once the model is up and running, it operates largely independently, applying the patterns it has learned to new data. There's minimal ongoing human intervention unless the model needs retraining or adjustment based on new data or requirements.
RLHF
On the other hand, RLHF takes a more dynamic approach to the reward function. Instead of relying solely on predefined rules, the model learns and adapts based on continuous feedback from human users. As the system makes decisions, humans provide feedback on the quality of these decisions.
Positive feedback encourages certain behaviors, while negative feedback discourages others. This method allows the model to learn flexibly and adapt to complex, real-world scenarios. Human involvement in RLHF is much more hands-on and continuous. Rather than just setting up the system and letting it run, humans actively provide feedback and guidance throughout the learning process.
This creates a more interactive and iterative learning environment where the model continuously evolves and improves based on the nuanced insights provided by human users. This ongoing interaction makes RLHF particularly effective for tasks that require a high degree of judgment.
How does RLHF work for language models?
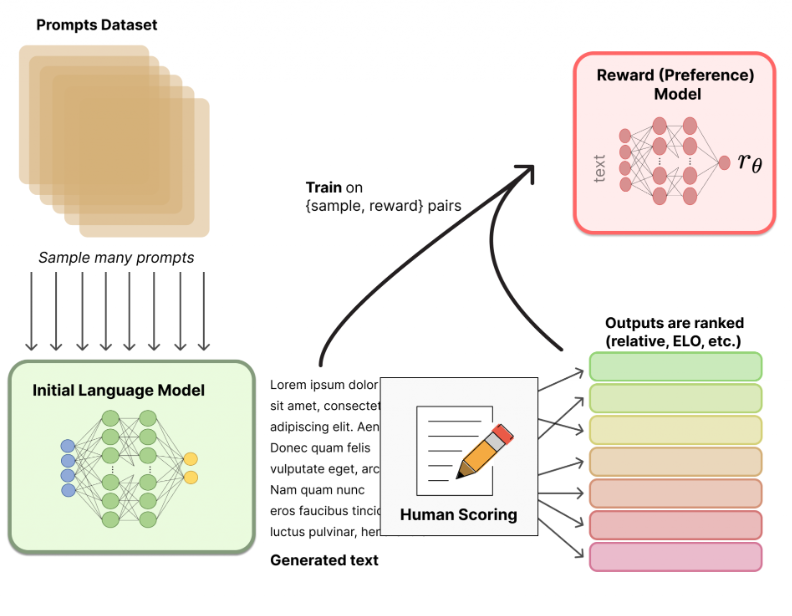
Reinforcement Learning from Human Feedback (RLHF) applied to language models involves a structured approach comprising three essential phases. These phases enable language models to learn and adapt based on human preferences, ultimately improving the quality of the generated text. Here's a more detailed breakdown of the RLHF process for language models:
Phase 1: Pre-training
RLHF starts with a pre-trained language model (LLM) because it's just more practical. These models, like GPT-3 or DeepMind's Gopher, already have a good grasp of language thanks to their training on a massive amount of data. This saves us the enormous effort and resources it would take to build a model from scratch.
Even though these LLMs are quite advanced, they aren't perfect — they don't always align perfectly with specific user needs or goals. That's where additional fine-tuning comes in, although it's not always necessary.
For example, OpenAI tweaked GPT-3 with human-generated text that reflected the kind of responses they wanted. Anthropic took another approach, distilling their model to focus on being helpful, honest, and harmless.
Choosing the right model to start with in RLHF isn't straightforward and depends a lot on the project's specific needs. It's a flexible and experimental area, where tweaking and fine-tuning can significantly improve how well the model aligns with human preferences, making them more useful in real-world applications.
Phase 2: Creating a reward model
The second phase focuses on establishing a reward model for the RL system. This involves training another machine learning model, which typically takes the form of another language model that has been adapted to output a scalar quality score rather than text tokens. This reward model is pivotal for assessing the quality of the text generated by the primary LLM.
To train the reward model, a dataset of LLM-generated text is needed, which is labeled for quality. The primary LLM is given a prompt to construct each training example and generates multiple outputs. Human evaluators are then tasked with ranking these outputs from best to worst. The reward model is trained to predict the ranking scores based on the text generated by the LLM. The reward model creates a mathematical representation of human preferences by learning from the LLM's output and the associated ranking scores.
Phase 3: Reinforcement learning loop
A reinforcement learning loop is established in the final phase. A copy of the primary LLM is transformed into the RL agent. During each training episode, the LLM receives prompts from a training dataset and generates text in response. The generated text is passed to the reward model, which assigns a score based on its alignment with human preferences. The LLM is then updated to generate text that scores higher according to the reward model.
This general framework serves as the foundation for RLHF in language models. However, it's important to note that specific implementations may incorporate variations. For instance, updating the main LLM can be computationally expensive, leading machine learning teams to freeze some of its layers to reduce training costs.
Balancing reward optimization with language consistency is another critical consideration. The reward model approximates human preferences and may not capture all nuances. Like other reinforcement learning systems, the agent LLM may find shortcuts to maximize rewards while potentially violating grammatical or logical consistencies. To address this, the ML engineering team retains a copy of the original LLM within the RL loop.
The difference between the output of the original LLM and the RL-trained LLM (referred to as the KL divergence) is integrated into the reward signal as a negative value. This helps prevent the model from deviating too far from the original output, ensuring a balance between reward optimization and language consistency.
What is the difference between RLHF and reinforcement learning?
Reinforcement Learning from Human Feedback (RLHF) and traditional reinforcement learning (RL) share the common goal of training intelligent agents to make decisions and take actions in environments. However, their primary difference lies in the source of guidance and feedback during the learning process.
In RL, the agent learns solely through trial and error, interacting with the environment to maximize cumulative rewards. It relies on exploration to discover optimal strategies, which can be time-consuming and inefficient, particularly in complex or high-dimensional environments. In contrast, RLHF integrates human expertise and feedback into the learning process.
Humans provide guidance through rewards, preferences, or demonstrations, significantly expediting learning and improving sample efficiency. This makes RLHF particularly useful when extensive exploration is impractical or costly. The human feedback acts as a more informative and directed signal for the agent to learn from.
Furthermore, RLHF introduces a more direct connection between human intent and machine behavior. In simple RL, the agent's understanding of the desired behavior is implicit in the reward function, whereas in RLHF, human feedback can explicitly convey intent and preferences. This is particularly advantageous in applications where human guidance is crucial, such as autonomous systems or personalized recommendation algorithms.
What are some benefits of RLHF?
Reinforcement Learning from Human Feedback (RLHF) offers several significant benefits, enhancing the effectiveness of machine learning models in various applications:
1. Efficiency in Learning: RLHF accelerates the learning process of models by leveraging human guidance. This results in faster convergence to optimal solutions, reducing the time and resources required for training.
2. Sample Efficiency: RLHF improves sample efficiency, allowing models to achieve high performance with fewer trials. This is particularly valuable in situations where extensive exploration is costly or impractical.
3. Customization and Adaptability: RLHF enables models to adapt to specific user preferences or requirements. This level of customization is essential for creating personalized recommendations, tailored solutions, and adaptable AI systems.
4. Robustness and Safety: Human feedback in RLHF helps models avoid risky or undesirable actions, enhancing their safety and robustness. This is critical in applications with paramount safety concerns, such as autonomous vehicles or healthcare decision support.
5. Improved Real-World Applicability: RLHF makes machine learning models more suitable for real-world scenarios by aligning their behavior with human expectations. This extends to areas like natural language processing, where models can generate more coherent and contextually relevant responses.
The Future of RLFH
RLFH is promising and has definitely caught the eye of the big AI research labs, but it's not without issues.
Even though the models are improving, they can still sometimes produce harmful or incorrect information without showing signs of doubt. This ongoing challenge keeps driving RLHF forward — since we're dealing with fundamentally human problems, there's no end point where we can say, "Okay, the model is perfect now."
Deploying a system with Reinforcement Learning from Human Feedback (RLHF) can be expensive, mostly because it involves hiring extra help. Unlike other models that might use crowdsourcing, RLHF needs well-crafted, human-generated texts, which typically means bringing in skilled part-time staff.
The effectiveness of RLHF really depends on the quality of human annotations. These come in two forms: one is creating texts to fine-tune the initial language model, like what was done with InstructGPT. The other is gathering human opinions to compare different model outputs. While collecting around 50,000 preference samples for training isn't too bad cost-wise, it's still a stretch for many academic budgets.
There's also the challenge of inconsistency in human annotations. People often have different views on what makes a good response, which can introduce a lot of variability in the training data. This makes developing reliable RLHF systems a bit tricky.
Despite its limitations, there's a lot of room for innovation in Reinforcement Learning from Human Feedback (RLHF), particularly in refining the RL optimizer. The commonly used Proximal Policy Optimization (PPO) is a bit dated, and there's no fundamental reason why other algorithms couldn't enhance the RLHF process. Experimenting with different algorithms could lead to improvements and new approaches within the RLHF workflow.
One of the significant costs in fine-tuning the language model (LM) policy involves evaluating every text output against the reward model, which serves as part of the environment in traditional RL setups.
This requires numerous forward passes of a large model, which can get expensive. An alternative could be using offline RL to optimize policies, potentially cutting these costs. New algorithms like Implicit Language Q-Learning (ILQL), recently discussed at CarperAI, seem particularly promising for this optimization.
Furthermore, some core aspects of the RL process, such as the balance between exploration and exploitation, haven't been fully explored in the context of RLHF. Diving into these areas could deepen our understanding of how RLHF works and potentially boost its performance.
Optimizing RLHF with advanced data labeling techniques
The trajectory of RLHF is inherently tied to its roots: human feedback. As this feedback drives the adaptation and improvement of language models, a systematic and efficient method for collecting and organizing this feedback becomes paramount.
Data labeling sits at the heart of this process. Rather than just amassing vast amounts of data, the focus is shifting towards the quality and precision of the labeled data. This pivot demands sophisticated data labeling tools that can efficiently gather, purify, and annotate data, especially as AI challenges become more intricate.
Enter Pareto.AI.
A state-of-the-art data labeling and RLHF platform designed to cater to the evolving needs of RLHF training for LLM development. In the constantly evolving world of RLHF, platforms like Pareto.AI ensure that the data driving these changes is of the highest quality and precision.
If you're interested in knowing more about how we help AI companies with critical data labeling and annotation projects, feel free to get in touch.